人工神经网络、深度学习方法和反向传播算法构成了现代机器学习和人工智能的基础。但现有方法往往是一个阶段更新网络权重,另一个阶段在使用或评估网络时权重保持不变。这与许多需要持续学习的应用程序形成鲜明对比。
最近,一篇发表在《nature》杂志上的研究论文《Loss of plasticity in deep continual learning》证明:标准的深度学习方法在持续学习环境中会逐渐失去可塑性(plasticity),直到它们的学习效果不比浅层网络好。

论文地址:https://www.nature.com/articles/s41586-024-07711-7
值得注意的是,人工智能先驱、强化学习教父、DeepMind 杰出研究科学家,阿尔伯塔大学计算机科学教授 Richard S. Sutton 是这篇论文的作者之一。
简单来说,该研究使用经典的 ImageNet 数据集、神经网络和学习算法的各种变体来展示可塑性的丧失。只有通过不断向网络注入多样性的算法才能无限期地维持可塑性。基于这种思路,该研究还提出了「持续反向传播算法」,这是反向传播的一种变体,其中一小部分较少使用的单元被持续随机地重新初始化。实验结果表明,基于梯度下降的方法是不够的,持续的深度学习需要随机的、非梯度的成分来保持可变性和可塑性。
ImageNet 数据库包含数百万张用名词(类别)标记的图像,例如动物类型和日常物品。典型的 ImageNet 任务是猜测给定图像的标签。
为了使 ImageNet 适应持续学习,同时最大限度地减少所有其他变化,该研究通过成对的类构建了一系列二元分类任务。例如,第一个任务可能是区分猫和房屋,第二个任务可能是区分停车标志和校车。利用数据集中的 1000 个类,该研究能够以这种方式形成 50 万个二元分类任务。
对于每个任务,该研究首先在两个类的图像子集上训练深度学习网络,然后在这些类的单独测试集上测量其性能。在一个任务上训练和测试后,下一个任务从一对不同的类开始。研究团队将此问题称为「持续 ImageNet(Continual ImageNet)」。在持续 ImageNet 中,任务的难度随着时间的推移保持不变。性能下降意味着网络正在失去学习能力,这是可塑性丧失的直接表现。
该研究将各种标准深度学习网络应用于 Continual ImageNet,并测试了许多学习算法和参数设置。为了评估网络在任务中的性能,该研究测量了正确分类测试图像的百分比。
该研究发现:对于经过良好调整的网络,性能往往首先提高,然后大幅下降,最终接近或低于线性基线。当性能开始下降时,网络架构、算法参数和优化器的具体选择会产生影响,但多种选择都会导致性能严重下降。标准深度学习方法在后续任务中无法比线性网络更好地学习,这直接证明这些方法在持续学习问题中效果不佳。
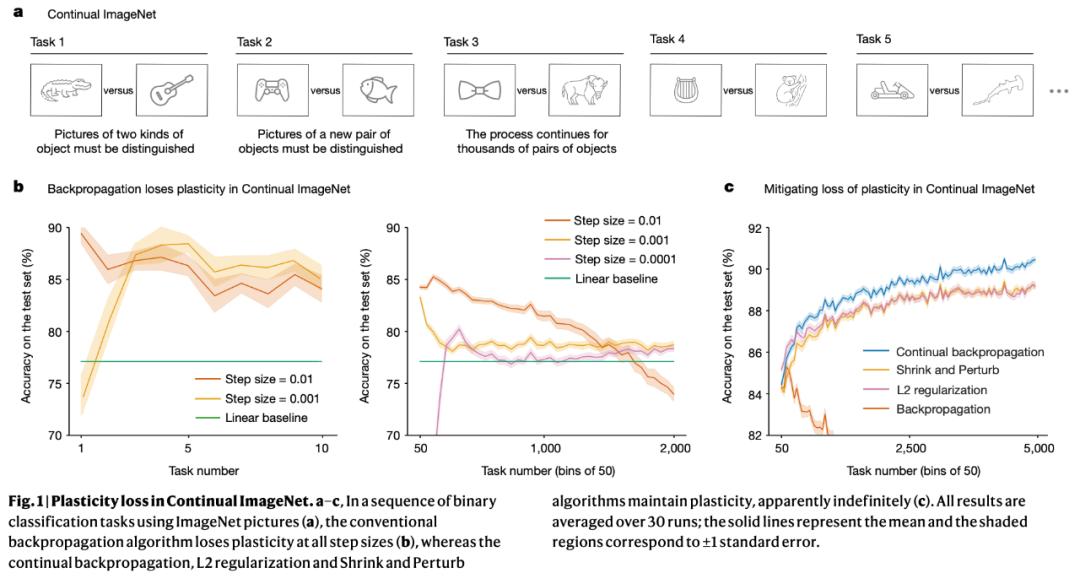
令人惊讶的是,Adam、Dropout 和归一化等流行方法实际上增加了可塑性的损失;而 L2 正则化在许多情况下减少了可塑性的损失。
研究团队发现:显式保持网络权重较小的算法通常能够保持可塑性,甚至在许多任务中能够提高性能。
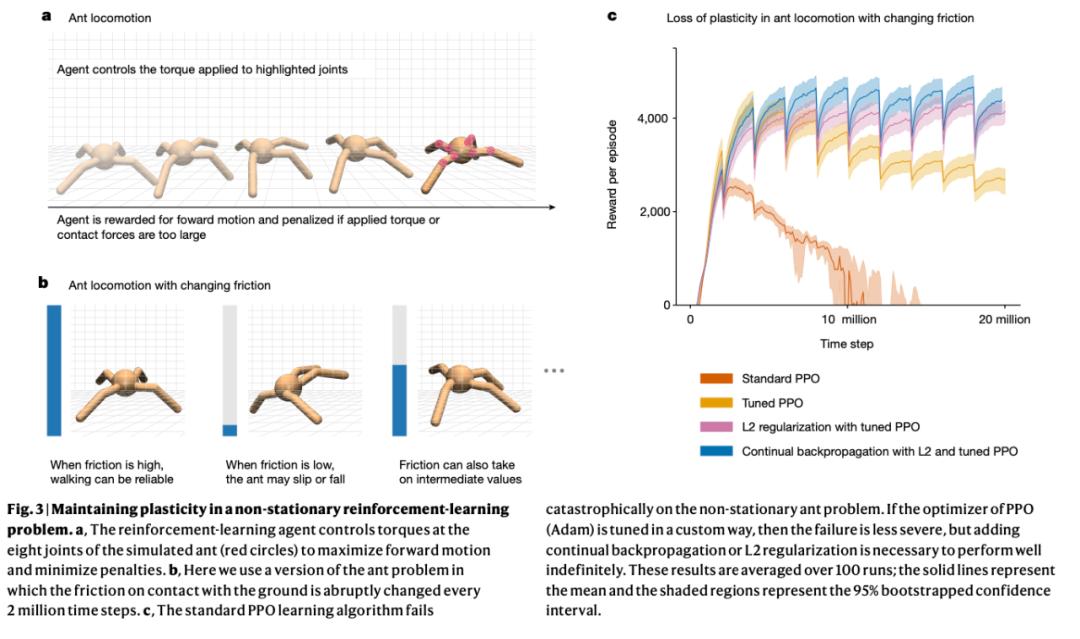
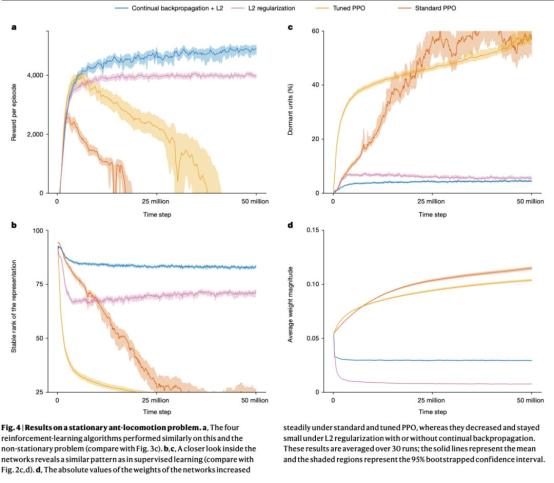
该研究基于上述发现,提出了反向传播算法的一种变体 —— 持续反向传播,该算法向网络注入可变性并保持其某些权重较小。
方法
持续反向传播
持续反向传播算法将选择性地对网络中低效的单元进行初始化处理。研究团队定义了名为「贡献效用」的值来衡量每个单元的重要性。如果神经网络中某个隐藏单元对它所连接的下游单元的影响很小,那么它的作用就可能被网络中其他更有影响力的隐藏单元掩盖。
贡献效用通过计算即时贡献的移动平均值来衡量,这个值由衰减率表示。在所有实验中,初始衰减率 η 设置为 0.99。在前馈神经网络中,第 l 层第 i 个隐藏单元在时间 t 的贡献效用
更新如下:
其中
是时间 t 时第 l 层第 i 个隐藏单元的输出,
代表其权重,
代表第 l+1 层的单元数量。
当一个隐藏单元被重新初始化时,它的输出的权重将被初始化为零。这么做是为了新添加的隐藏单元不会影响模型已经学到的功能。但是这样也容易导致新的隐藏单元很快被重新初始化。
为了防止这种情况,研究团队设置了「成熟阈值」,在 m 次更新前,即使新的隐藏单元的效用是零,也不会被重新初始化。当更新次数超过 m 后,每一步「成熟单元」的一部分 ρ(称为替换率),在每一层都会被重新初始化。替换率 ρ 通常设置为一个非常小的值,这意味着在数百次更新后只替换一个单元。例如,在 CIFAR-100 中,研究团队将替换率设置为 10 的负五次方,每一步,大约 0.00512 个单元被替换。这相当于大约每 200 次更新替换一次。
最终的算法结合了传统的反向传播和选择性重新初始化两种方法,以持续地从初始分布中引入随机单元。每次更新时,持续反向传播将执行梯度下降并选择性地重新初始化。
前馈神经网络的持续反向传播如算法1所示。处理小批量数据时,可以采取一种更经济的方法:通过对小批量数据上的即时贡献效用取平均值,而不是保持一个运行平均值来节省计算量。


在 ImageNet 上的应用
研究使用了包含 1000 个类别的 ImageNet 数据库,每个类别有 700 张图片,分为 600 张训练图像和 100 张测试图像。在二元分类任务中,网络首先在 1200 张训练图像上训练,然后在 200 张测试图像上评估分类准确度。
所有在持续 ImageNet 上使用的算法都采用了具有三个卷积加最大池化(convolutional-plus-max-pooling)层和三个全连接层的卷积网络。最终层有两个单元,对应两个类别。在任务变更时,这些单元的输入权重会重置为零。这种做法在深度持续学习中是标准做法,尽管它为学习系统提供了关于任务变化时间的特权信息。
线性网络的性能在持续 ImageNet 上不会下降,因为它在每个任务开始时都会重置。通过在数千个任务上取均值,得到线性网络性能的低方差估计值,作为基线。
网络使用带有动量的 SGD 在交叉熵损失上进行训练,动量参数设为 0.9。研究者测试了不同的步长参数,但为了清晰起见,只展示了 0.01、0.001 和 0.0001 的步长性能。
该研究还通过网格搜索确定了 L2 正则化、收缩和扰动以及持续反向传播算法的超参数,以在 5000 个任务上获得最高的平均分类准确度。L2 正则化和收缩扰动的超参数包括步长、权重衰减和噪声方差,持续反向传播的超参数包括步长和替换率,成熟度阈值设为 100。
研究者对所有超参数集合进行了 10 次独立运行,然后对表现最佳的超参数集合进行了额外的 20 次运行,总共 30 次。
CIFAR-100 的类别增量学习
在 CIFAR-100 的类别增量学习中,开始时,模型可以识别 5 种类型的图片,随着训练时间越来越长,模型能识别的图片种类越来越多,比如能同时学习 100 种类别的图片。在这个过程中,系统将通过测试检验自己的学习效果。数据集由 100 个类别组成,每个类别有 600 张图像,其中 450 张用于创建训练集,50 张用于验证集,100 张用于测试集。
每次增加学习的类别后,网络被训练 200 个周期,总共增加 20 次,共训练 4000 个周期。研究团队在前 60 个周期中将学习率设置为 0.1,接下来的 60 个周期为 0.02,此后的 30 个周期为 0.004,最后的 40 个周期为 0.0008。在每次增加的 200 个周期中,研究团队选出了在验证集上准确度最高的网络。为了防止过拟合,在每轮训练中,新网络的权重将被重置为上一轮准确度最高网络的权重。
他们选择了 18 层的 ResNet 做实验。在将输入图像呈现给网络之前,该研究进行了几个步骤的数据预处理。首先,将每张图像中所有像素的值重新缩放到 0 和 1 之间。然后,每个通道中的每个像素值通过该通道像素值的平均值和标准差分别进行中心化和重新缩放。最后,在将图像输入给网络之前,该研究对每张图像应用了三种随机数据转换:以 0.5 的概率随机水平翻转图像,通过在每边填充 4 个像素然后随机裁剪到原始大小来随机裁剪图像,以及在 0-15° 之间随机旋转图像。预处理的前两步应用于训练集、验证集和测试集,但随机转换仅应用于训练集中的图像。
该研究测试了多个超参数,以确保在特定架构下保持每个算法的最佳性能。对于基础系统,该研究测试的权重衰减参数取值范围为 {0.005, 0.0005, 0.00005}。对于「持续反向传播」,该研究测试的成熟度阈值取值范围为 {1000, 10000},替换率的取值范围为
,采用了公式 (1) 中描述的贡献效用。成熟度阈值为 1000,替换率为 10^(-5) 时,表现最佳。
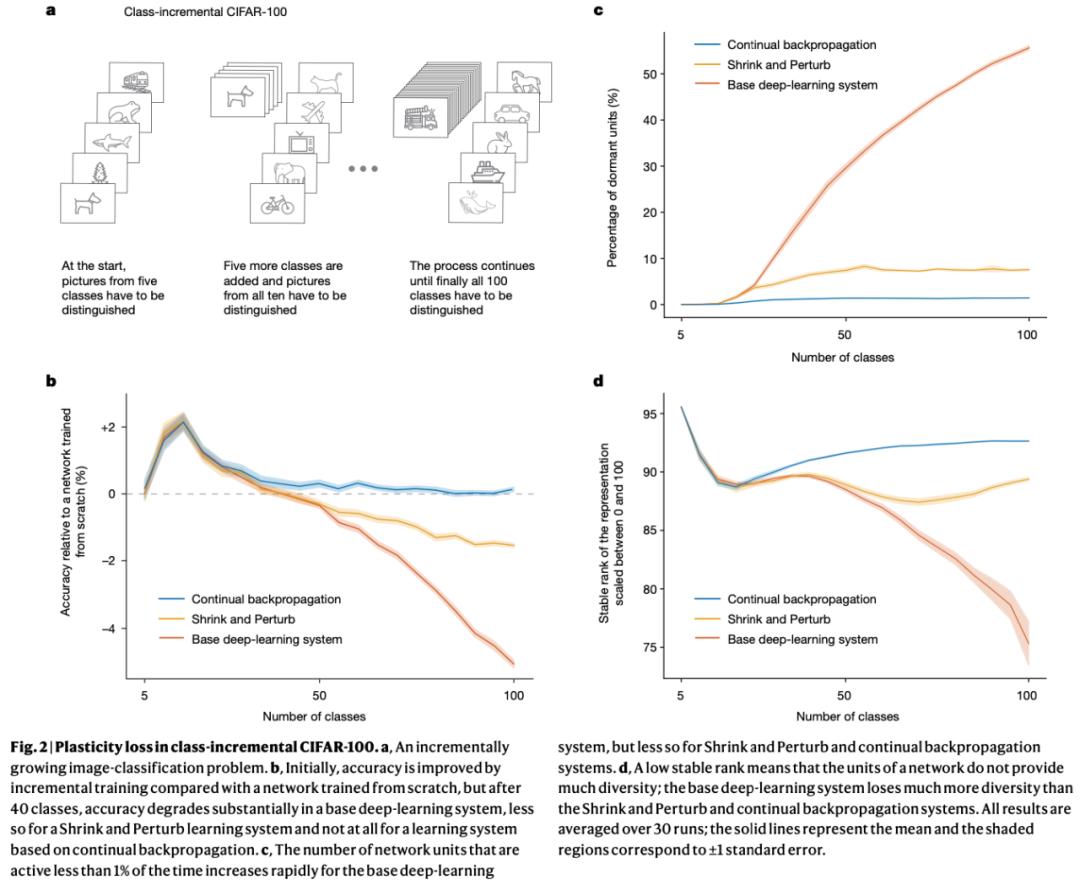
作为参考,该研究还实现了一个具有与基础系统相同超参数的网络,但在每次增量的开始时都会重新初始化。图 2b 显示了每个算法相对于重新初始化网络的性能表现。
持续反向传播在全部的 100 个类别中的最终准确率为 76.13%,而扩展数据图 1b 展示了在成熟度阈值为 1000 时,持续反向传播在不同替换率下的性能表现。
原标题:《深度学习还不如浅层网络?RL教父Sutton持续反向传播算法登Nature》
